How Blutgang works on the inside
Yesterday, I announced Blutgang, the fastest load balancer and cache for Ethereum. The response has been excellent! I hope you enjoy Blutgang as much as I enjoyed building it.
Today, I want to talk about how blutgang works. The what, the how, and the why of why I designed Blutgang the way it is now. It will get pretty technical and cover some pretty advanced topics, so feel free to skip this one if you don’t care about all that. This article is written in a very schizophrenic, informal tone. I hope I live up to my blog description of makemake’s schizophrenic ramblings and that I redeem my previous sanely written articles with this one.
Why I built it
I encountered an issue when building and adding features to Sothis. The idea behind Sothis was to replay the historical state for testing, which works, albeit very slowly. And the reason was that I needed RPC queries. And I needed a lot of them.
So, I floated the idea of adding a feature to anvil that would rotate between RPCs.


web3-proxy looked like what I was after, so I looked closer.
PAYMENT CONTRACTS? REDIS? MYSQL???? ON MY LOAD BALANCER??????????????
I didn’t have it in me to run such bloat on my computer. While these might make sense for llamanodes, I didn’t need to deal with payments or rate limiting. And if I was building a fully commercial oriented product, I personally wouldn’t want my load balancer to handle these things. Any sane person would, at this point, either give up or subject themselves to running a MySQL server for their Ethereum load balancer.(afaik its optional, but still)
Unfortunately for me, I am pretty autistic, so I set out to build my own with the following goals:
- Be fast, potentially the fastest.
- Be easy to use. You should be able to install and run it in 2 commands max.
- Abuse modern computer architecture features.
- Be as lightweight as possible.
- NO BLOAT. Do one thing and do it extremely well. Keep it simple and keep it unix-ish.
Load balancing
Upon startup, blutgang will create an HTTP server to process incoming requests. If the request isn’t cached(we’ll get to how that’s handled later), an RPC will be chosen to serve our request. (the following code snippets are taken out of context and might not make sense. I’ll explain why I did things the way I did as I go.)
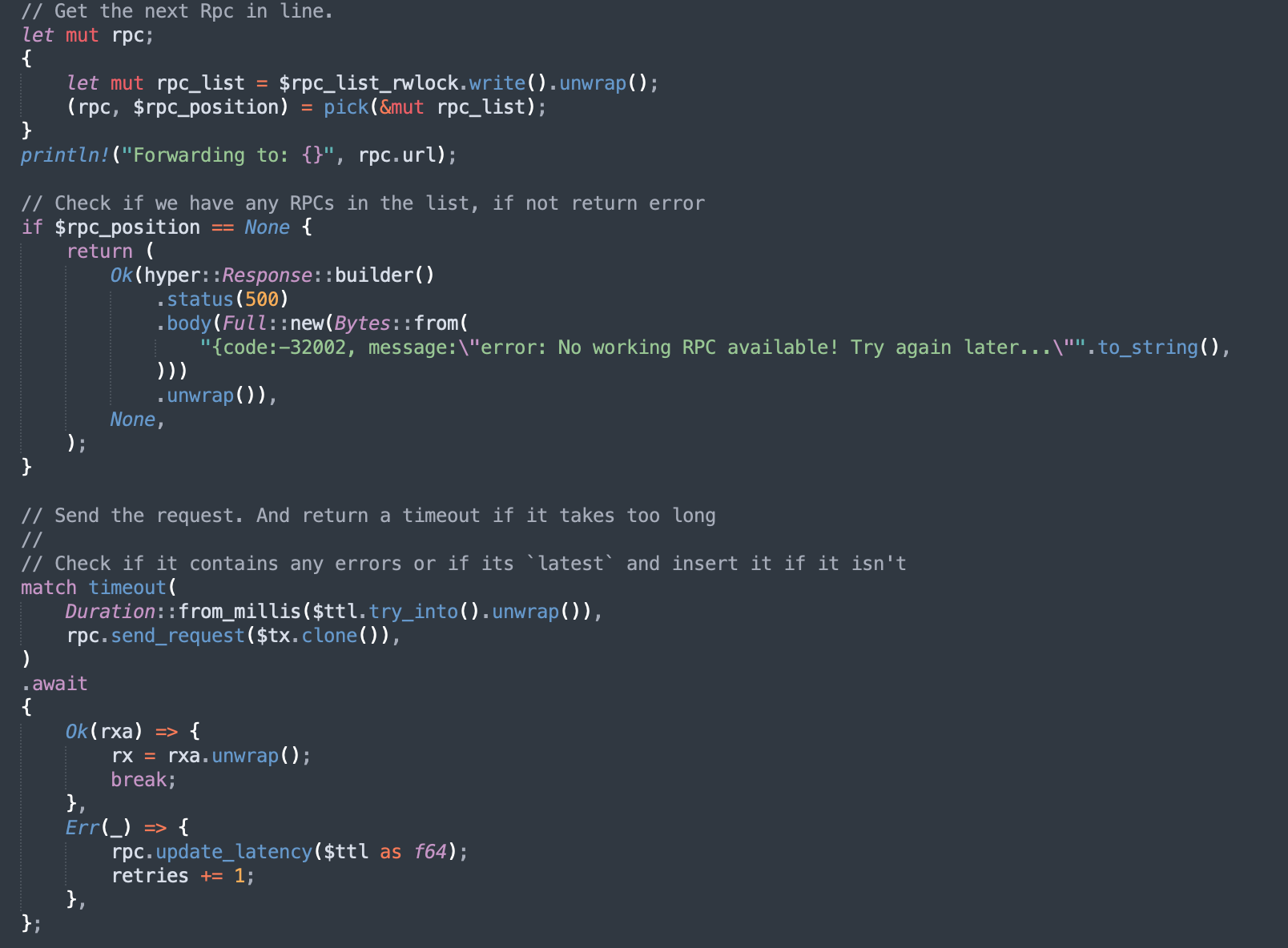
We use the pick function, a generic entrypoint to our selection algo. This is an area I’m looking to optimize in the future. You could have a separate task/thread run the selection algo periodically and send the results to requesting tasks via channels. Requesting tasks could also ask for a new RPC. This should reduce the blocking we must do due to acquiring the write lock on the rpc_list. If someone better at Rust than me sees this and thinks I’m chatting shit, please scream at me on social media. I am still recovering from go brainrot. Cheers 🥂
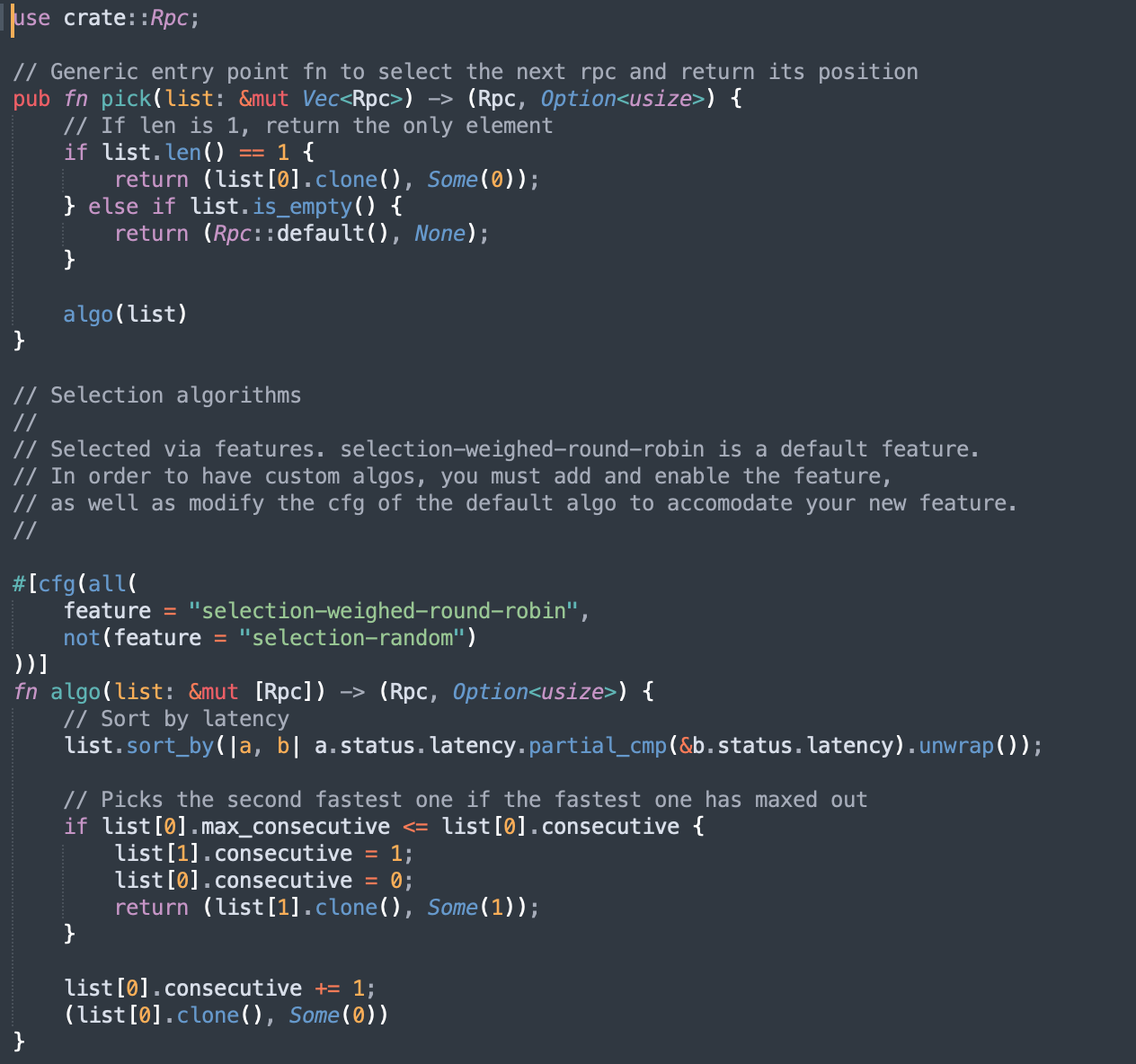
For the weighted round-robin algo, we sort the RPCs by latency, and if we used an RPC too much, we pick the second one. Latency? Yes! We record latency as well as consecutive hits.
We have a ttl variable set by the user, which tells us how long we’ll wait for an RPC to deliver us a response. If it takes too long, it will get dropped (we’ll get to that as well), and a new one will be picked. We repeat this process until we find a suitable RPC or run out of working ones.
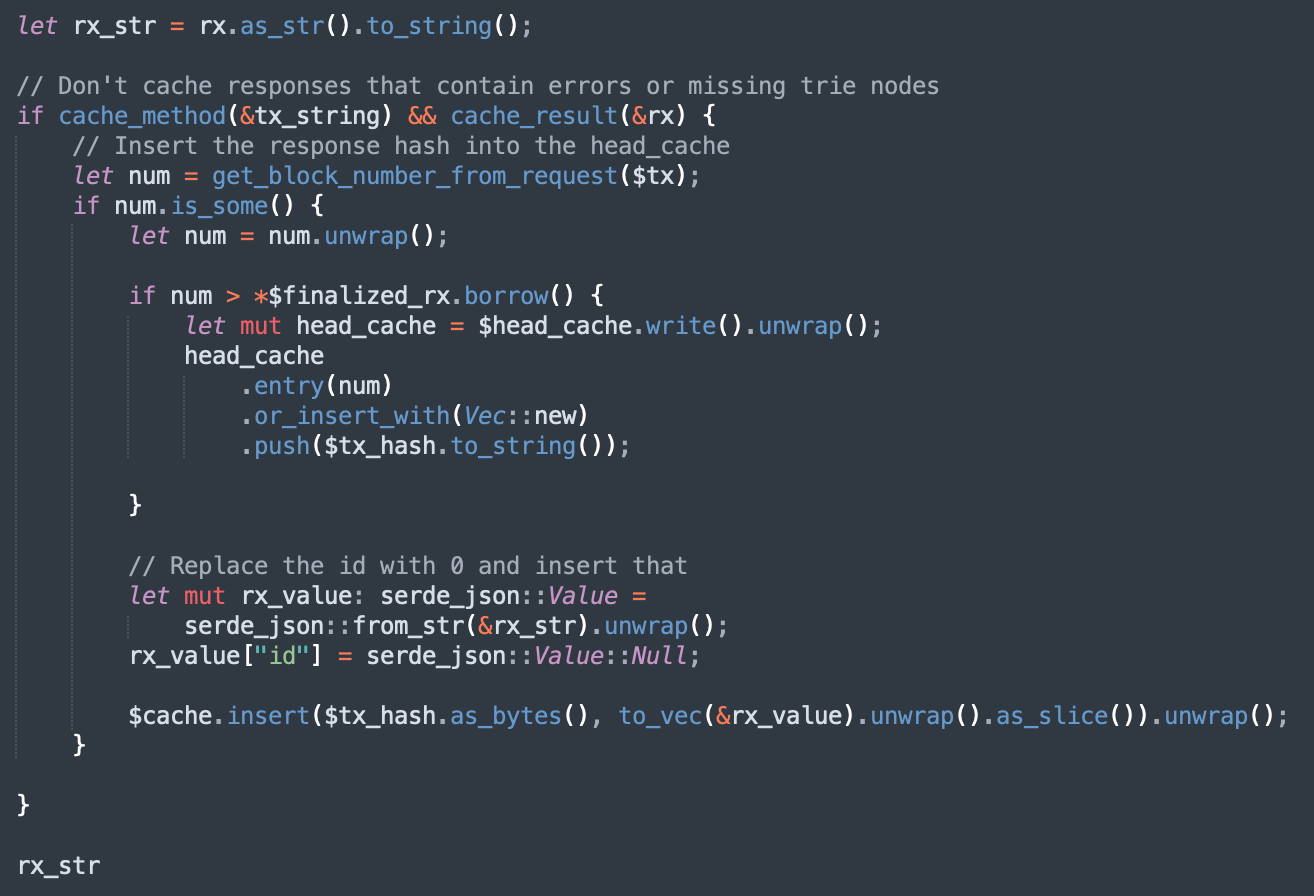
Once we get a response, we check if it can be hashed. If it can, we do an additional check if it’s beyond the finalized block. If it is, the request hash gets added to the head_cache, which stores the DB keys of unfinalized requests (TOO MUCH STUFF TO GO OVER NOW).
This approach works well for what we’re after. All of these checks and heap allocations end up being worth it. While I concede that this can be made more efficient, when the main bottleneck here is RPC performance, which wildly varies, it doesn’t matter if we shave off a few microseconds by avoiding the heap.
And speaking of tiny optimizations, im using AVX ISA extensions to reduce how long we spend on processing the response/request for caching by around 1000x. This shaves off a few nanoseconds, which adds up when processing a billion requests per second.
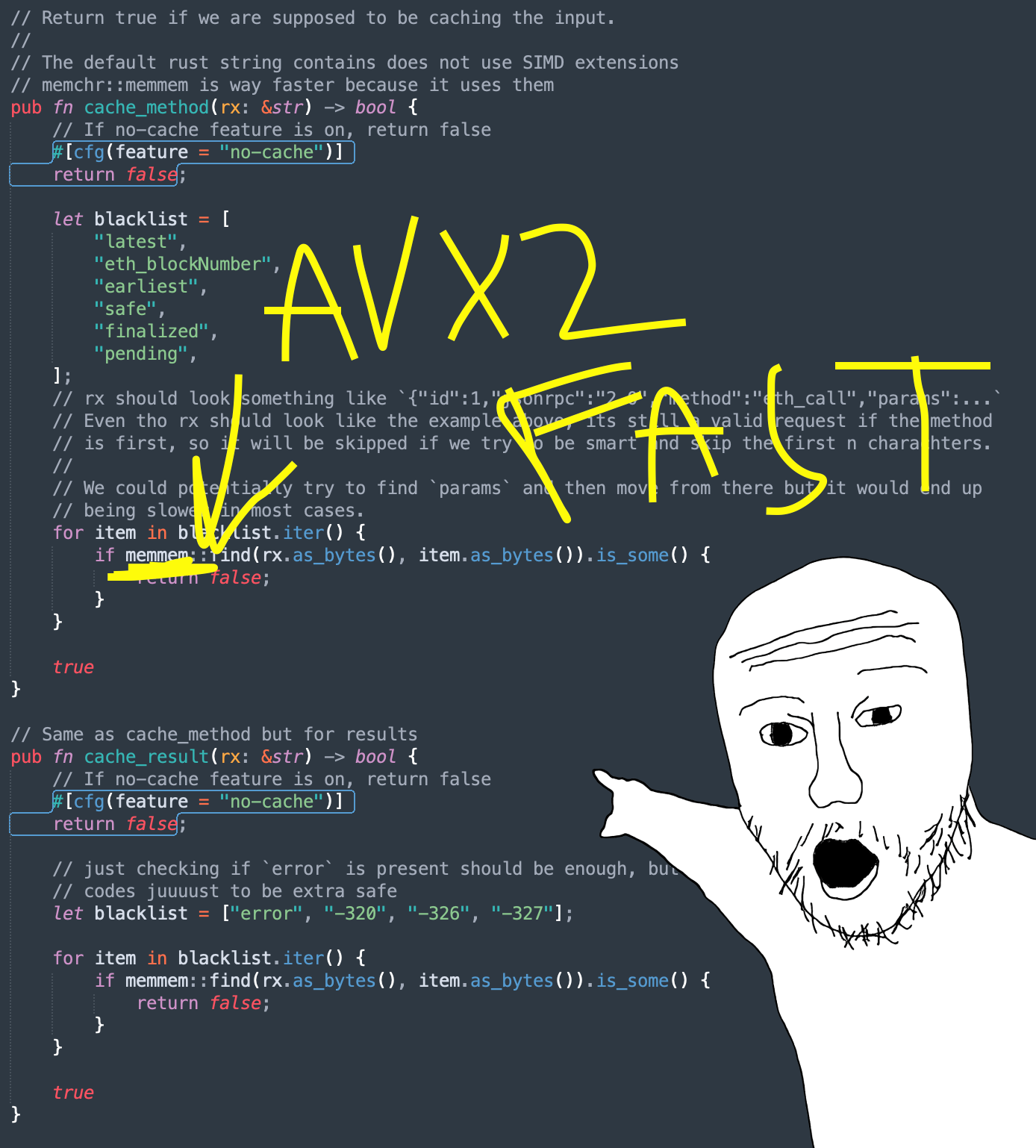
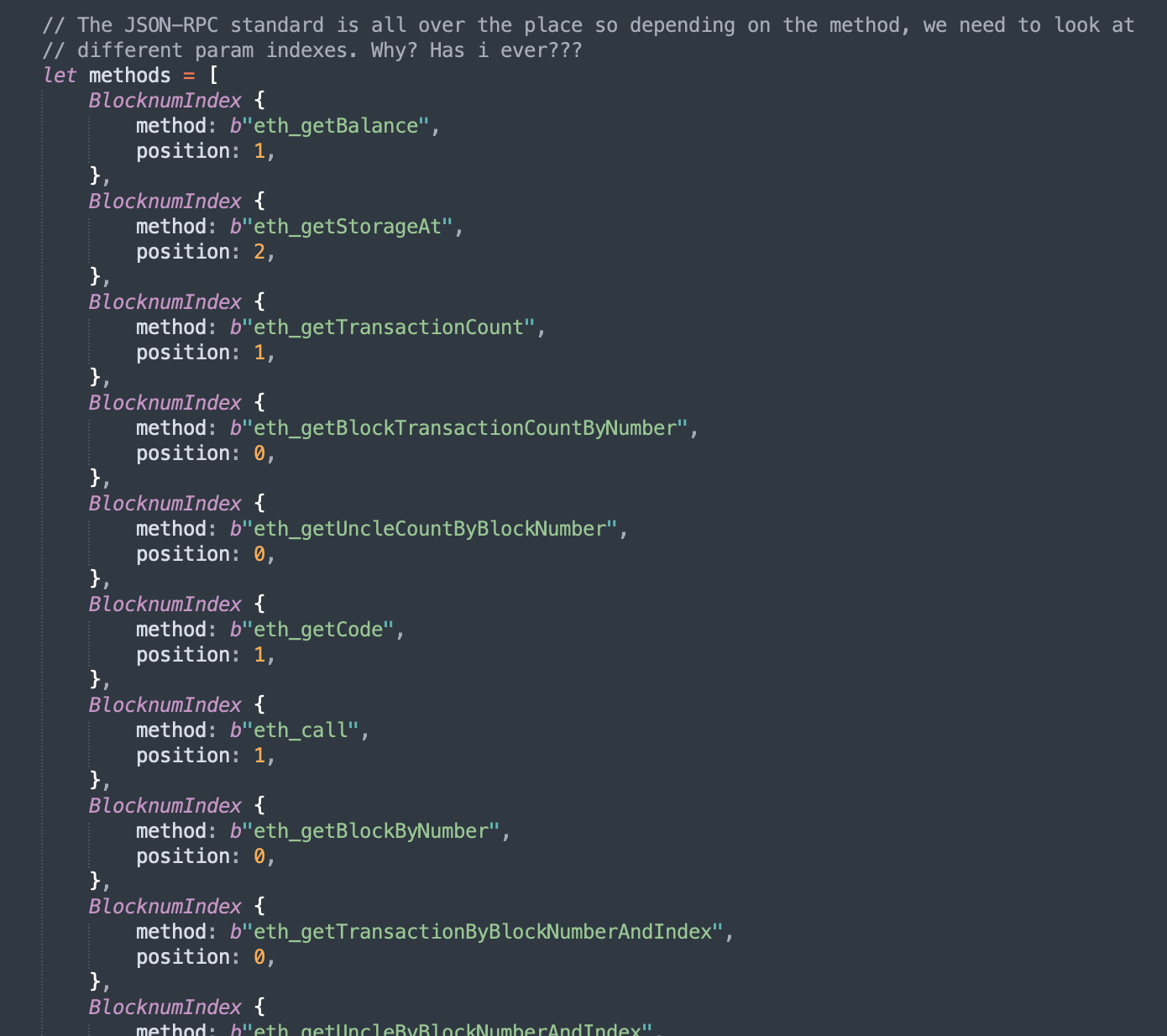
Also, the following code(comments) is a good representation of my sanity dwindling because of having to deal with Ethereums JSON-RPC standard:
Caching
I chose sled for the DB mainly because it was shilled to me by Treyzania. Once I dug into it, it had the best tradeoffs between speed/stability/storage for what I needed. If you used btreemap in Rust, you already know how to use sled. It’s super intuitive, with batching and range queries. Thanks, Trey!
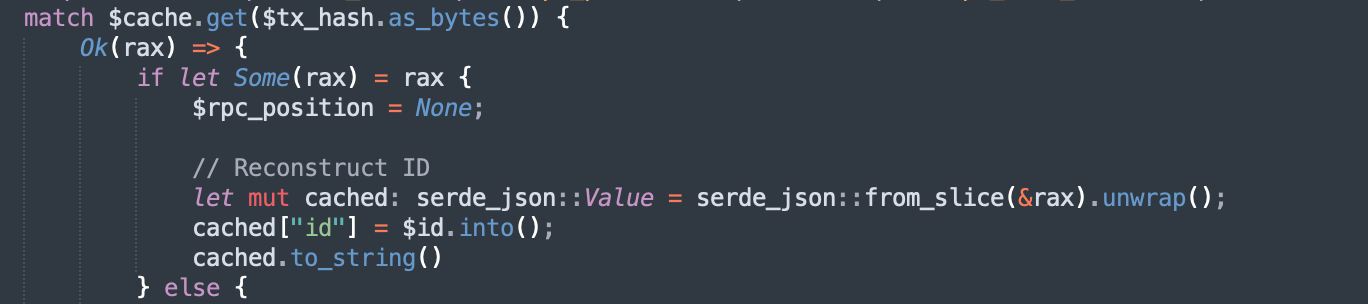
We set the id to 0, hash that with blake3(super fast), and use that as the key for the DB. If it’s None, that means it’s not cached, and we have to query a node; if it is, return that and set the original ID back. Pretty simple.
Health check
Health checking is pretty simple. We go over all the RPCs, check which ones are falling behind or taking too long, and remove them from the active queue. We also check to put them back if they are cooperating again.
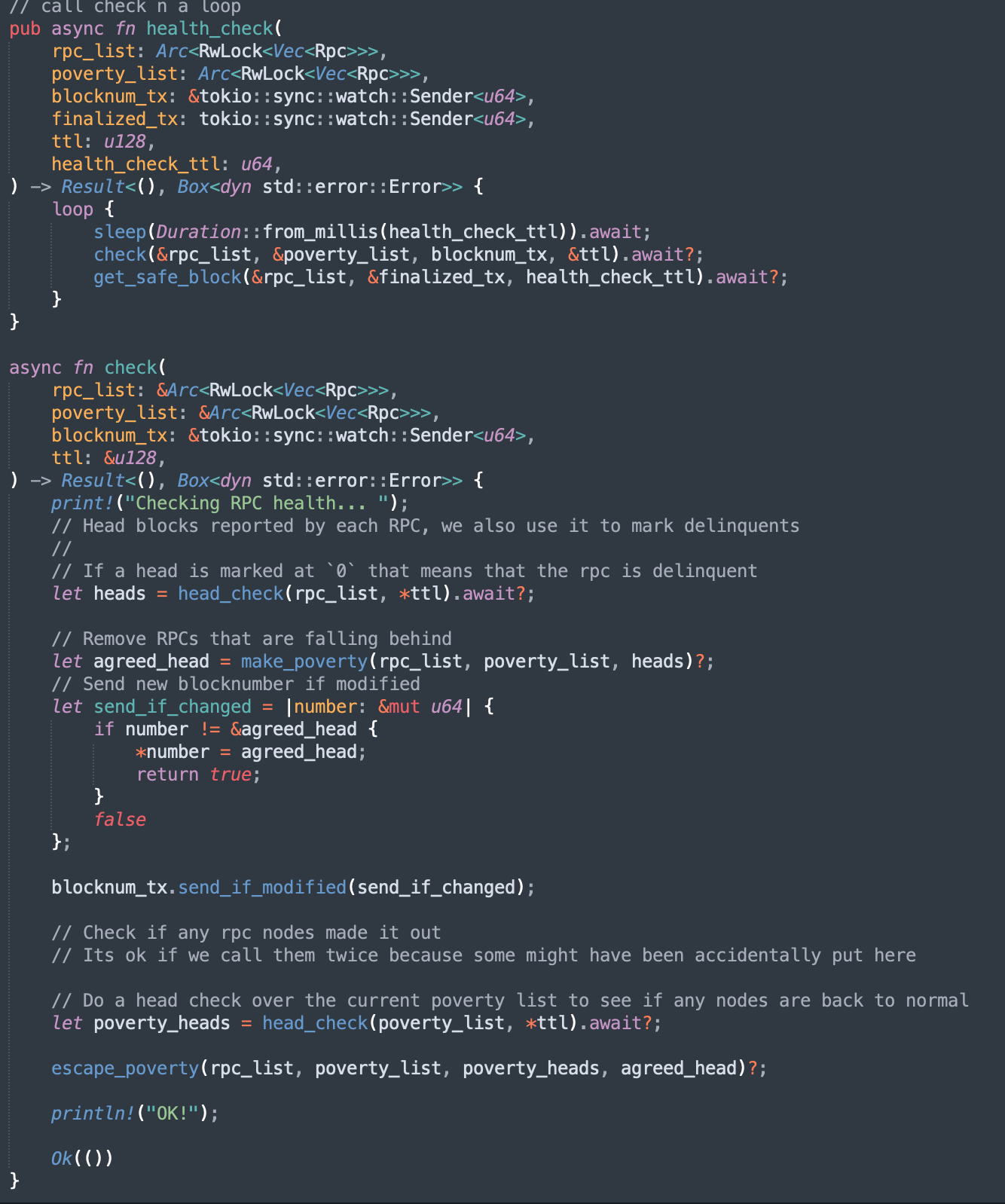
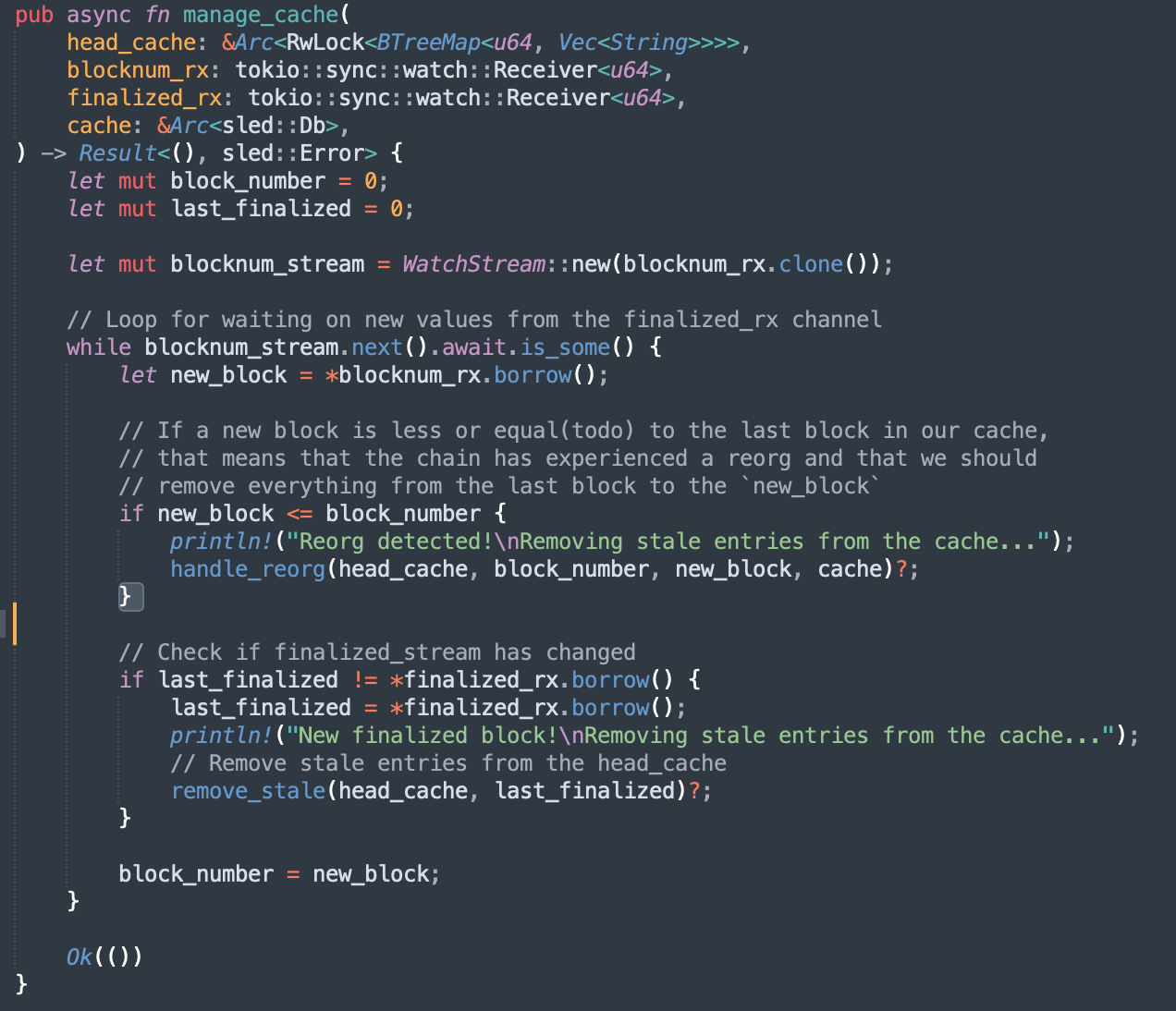
Reorg handling
We run a dedicated thread that waits for new finalized block updates from health_check to see if there are any changes we need to make to our database/head_cache.
If a new block is finalized, we go over stale keys in the head_cache and remove them.
In case of a reorg, we remove all affected unfinalized entries from the sled cache. The keys for these entries are stored in the head_cache. This makes handling reorgs of any depth very efficient. Sled is really good at doing these batched insertions/removals, so this works great for us.
Benchmarks
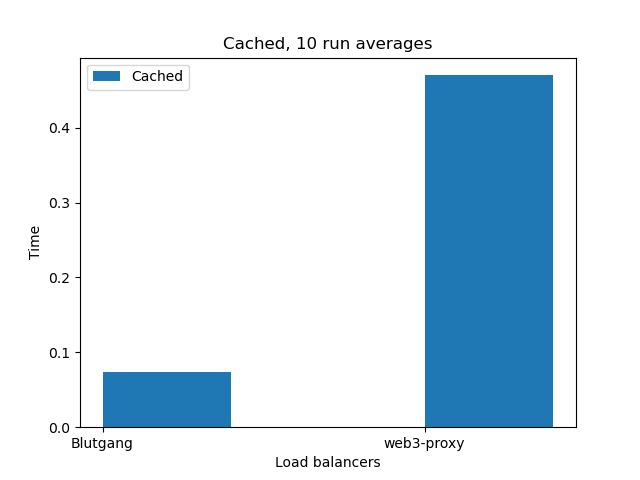
Blutgang destroys everything in the benchmarks I did. web3-proxy was 4x slower, and proxyd was so inconsistent I couldn’t gather meaningful data. Since it is written in Go(disgusting) and uses Redis, it should be somewhere around web3-proxy.
What is missing and what can be improved
From here, Blutgang can be optimized further by reducing as many heap allocations as possible and reducing blocking wherever we can.
Blutgang also does not support WebSockets, which is problematic because our users want to always be at the head. SSL and rate limiting are out of scope and should be handled by something like NGINX. If enough people complain, I might add it.
Conclusion
I started with the expectation of blutgang being the fastest, but I was surprised to find out how much it would be faster. And I am very proud of how it turned out, even tho there’s still room for improvements everywhere.
If you are a regular reader, you should learn Rust and contribute some code. If you already know how to program even better! It doesn’t have to be blutgang or Sothis. Just contribute some code. Be the change you want to see! The satisfaction I received from finally unveiling Blutgang to the general public was unparalleled. It truly feels great to build something useful to others and yourself.
If you are looking for rust developers, you should hire me. Contact info is down below :^)
